Molecular evolution (B)
Molecular evolution (B)
Molecular phylogeny of genes
|
Molecular phylogeny of genes
Molecular phylogeny of genes (B)
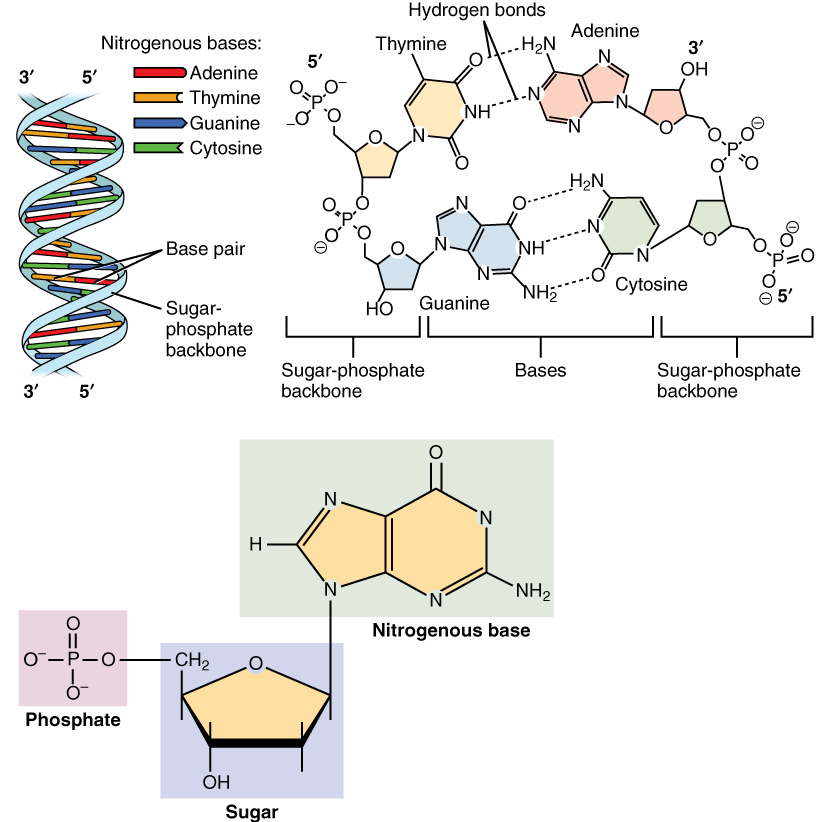
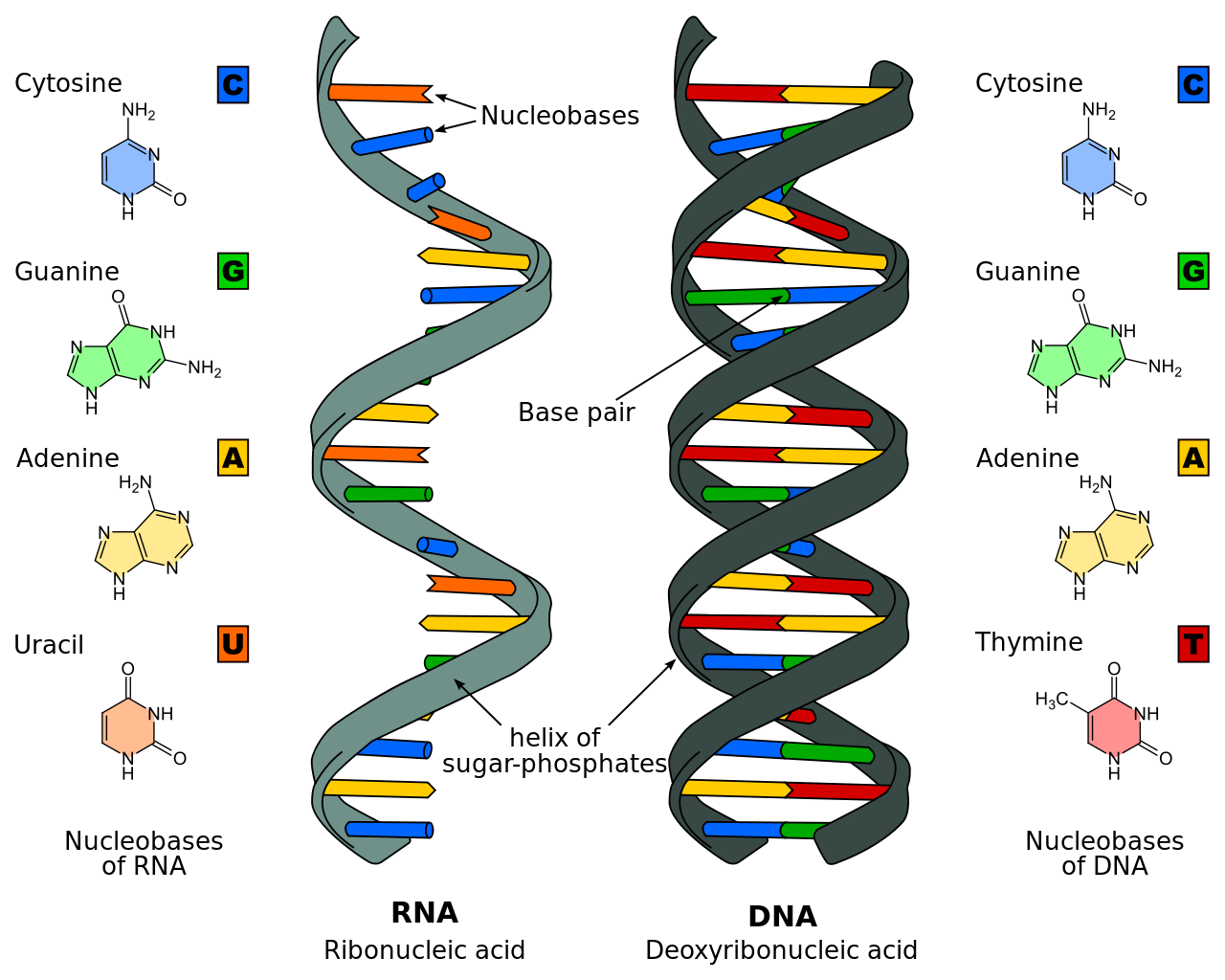
The methods for obtaining the nucleotide sequences of DNA have enormously improved since the 1980s and have become largely automated. Many genes have been sequenced in numerous organisms, and the complete genome has been sequenced in various species ranging from humans to viruses. The use of DNA sequences has been particularly rewarding in the study of gene duplications. The genes that code for the hemoglobins in humans and other mammals provide a good example.
Knowledge of the amino acid sequences of the hemoglobin chains and of myoglobin, a closely related protein, has made it possible to reconstruct the evolutionary history of the duplications that gave rise to the corresponding genes. But direct examination of the nucleotide sequences in the genes coding for these proteins has shown that the situation is more complex, and also more interesting, than it appears from the protein sequences.
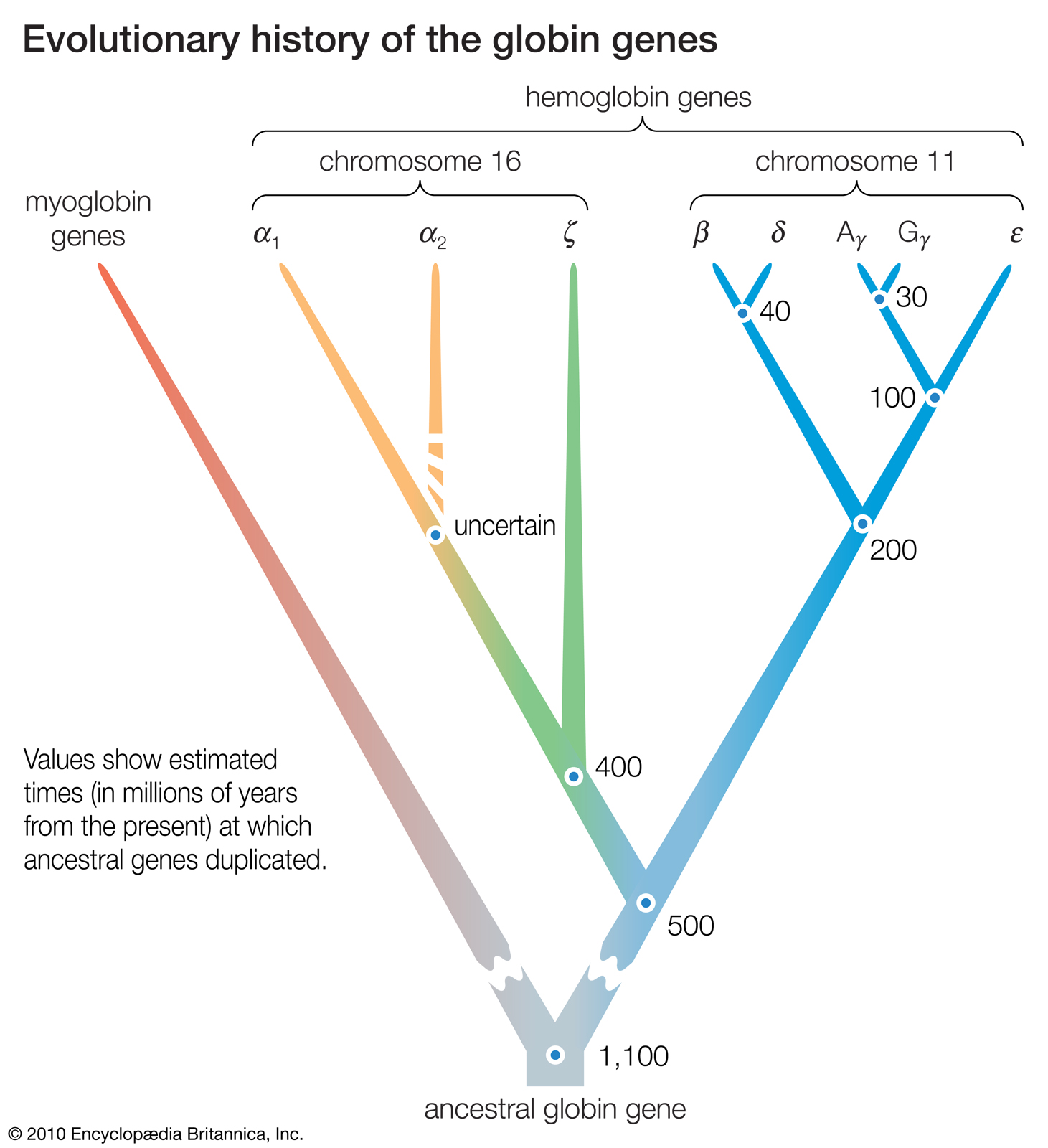
DNA sequence studies on human hemoglobin genes have shown that their number is greater than previously thought. Hemoglobin molecules are tetramers (molecules made of four subunits), consisting of two polypeptides (relatively short protein chains) of one kind and two of another kind. In embryonic hemoglobin E, one of the two kinds of polypeptide is designated ε; in fetal hemoglogin F, it is γ; in adult hemoglobin A, it is β; and in adult hemoglobin A2, it is δ. (Hemoglobin A makes up about 98 percent of human adult hemoglobin, and hemoglobin A2 about 2 percent). The other kind of polypeptide in embryonic hemoglobin is ζ; in both fetal and adult hemoglobin, it is α. The genes coding for the first group of polypeptides (ε, γ, β, and δ) are located on chromosome 11; the genes coding for the second group of polypeptides (ζ and α) are located on chromosome 16.
There are yet additional complexities. Two γ genes exist (known as Gγ and Aγ), as do two α genes (α1 and α2). Furthermore, there are two β pseudogenes (ψβ1 and ψβ2) and two α pseudogenes (ψα1 and ψα2), as well as a ζ pseudogene. These pseudogenes are very similar in nucleotide sequence to the corresponding functional genes, but they include terminating codons and other mutations that make it impossible for them to yield functional hemoglobins.
The similarity in the nucleotide sequence of the polypeptide genes, and pseudogenes, of both the α and β gene families indicates that they are all homologous — that is, that they have arisen through various duplications and subsequent evolution from a gene ancestral to all. Moreover, homology also exists between the nucleotide sequences that separate one gene from another. The evolutionary history of the genes for hemoglobin and myoglobin is summarized in the figure. |
|

|
|
|
|
| |
Multiplicity and rate heterogeneity
|
Multiplicity and rate heterogeneity
Multiplicity and rate heterogeneity (B)
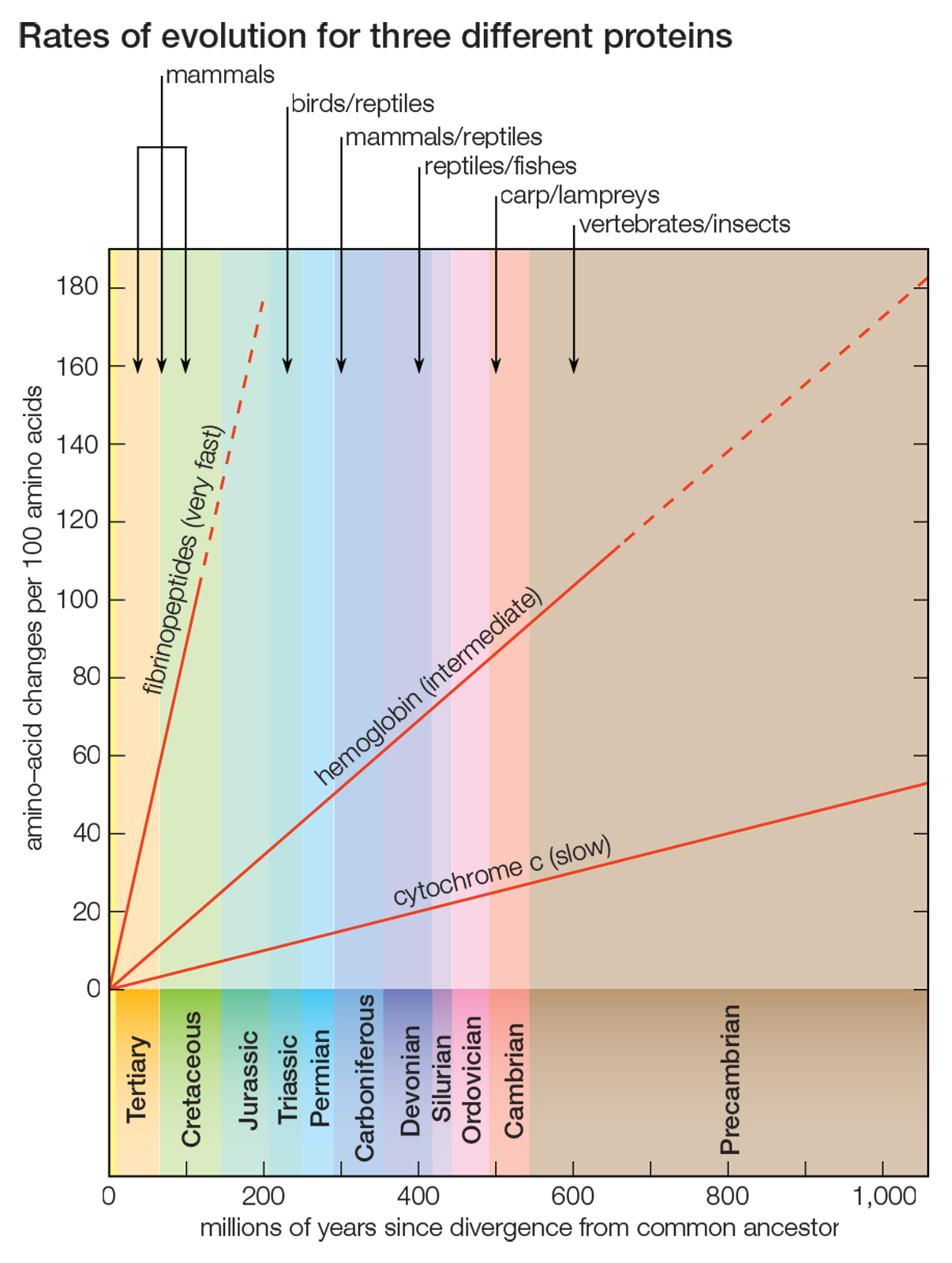
Cytochrome c consists of only 104 amino acids, encoded by 312 nucleotides. Nevertheless, this short protein stores enormous evolutionary information, which made possible the fairly good approximation, shown in the figure, to the evolutionary history of 20 very diverse species over a period longer than one billion years. But cytochrome c is a slowly evolving protein. Widely different species have in common a large proportion of the amino acids in their cytochrome c, which makes possible the study of genetic differences between organisms only remotely related. For the same reason, however, comparing cytochrome c molecules cannot determine evolutionary relationships between closely related species. For example, the amino acid sequence of cytochrome c in humans and chimpanzees is identical, although they diverged about 6 million years ago; between humans and rhesus monkeys, which diverged from their common ancestor 35 million to 40 million years ago, it differs by only one amino acid replacement.
Proteins that evolve more rapidly than cytochrome c can be studied in order to establish phylogenetic relationships between closely related species. Some proteins evolve very fast; the fibrinopeptides — small proteins involved in the blood-clotting process — are suitable for reconstructing the phylogeny of recently evolved species, such as closely related mammals. Other proteins evolve at intermediate rates; the hemoglobins, for example, can be used for reconstructing evolutionary history over a fairly broad range of time (see figure). |
|
| One great advantage of molecular evolution is its multiplicity, as noted above in the section DNA and protein as informational macromolecules. Within each organism are thousands of genes and proteins; these evolve at different rates, but every one of them reflects the same evolutionary events. Scientists can obtain greater and greater accuracy in reconstructing the evolutionary phylogeny of any group of organisms by increasing the number of genes investigated. The range of differences in the rates of evolution between genes opens up the opportunity of investigating different sets of genes for achieving different degrees of resolution in the tree, relying on slowly evolving ones for remote evolutionary events. Even genes that encode slowly evolving proteins can be useful for reconstructing the evolutionary relationships between closely related species, by examination of the redundant codon substitutions (nucleotide substitutions that do not change the encoded amino acids), the introns (noncoding DNA segments interspersed among the segments that code for amino acids), or other noncoding segments of the genes (such as the sequences that precede and follow the encoding portions of genes); these generally evolve much faster than the nucleotides that specify the amino acids. |
|
|
|
|
| |
The molecular clock of evolution
|
The molecular clock of evolution
The molecular clock of evolution (B)
One conspicuous attribute of molecular evolution is that differences between homologous molecules can readily be quantified and expressed, as, for example, proportions of nucleotides or amino acids that have changed. Rates of evolutionary change can therefore be more precisely established with respect to DNA or proteins than with respect to phenotypic traits of form and function. Studies of molecular evolution rates have led to the proposition that macromolecules may serve as evolutionary clocks.
It was first observed in the 1960s that the numbers of amino acid differences between homologous proteins of any two given species seemed to be nearly proportional to the time of their divergence from a common ancestor. If the rate of evolution of a protein or gene were approximately the same in the evolutionary lineages leading to different species, proteins and DNA sequences would provide a molecular clock of evolution. The sequences could then be used to reconstruct not only the sequence of branching events of a phylogeny but also the time when the various events occurred.
Consider, for example, the figure depicting the 20-organism phylogeny. If the substitution of nucleotides in the gene coding for cytochrome c occurred at a constant rate through time, one could determine the time elapsed along any branch of the phylogeny simply by examining the number of nucleotide substitutions along that branch. One would need only to calibrate the clock by reference to an outside source, such as the fossil record, that would provide the actual geologic time elapsed in at least one specific lineage.
The molecular evolutionary clock, of course, is not expected to be a metronomic clock, like a watch or other timepiece that measures time exactly, but a stochastic clock like radioactive decay. In a stochastic clock the probability of a certain amount of change is constant (for example, a given quantity of atoms of radium-226 is expected, through decay, to be reduced by half in 1,620 years), although some variation occurs in the actual amount of change. Over fairly long periods of time a stochastic clock is quite accurate. The enormous potential of the molecular evolutionary clock lies in the fact that each gene or protein is a separate clock. Each clock “ticks” at a different rate—the rate of evolution characteristic of a particular gene or protein—but each of the thousands and thousands of genes or proteins provides an independent measure of the same evolutionary events.
Evolutionists have found that the amount of variation observed in the evolution of DNA and proteins is greater than is expected from a stochastic clock—in other words, the clock is erratic. The discrepancies in evolutionary rates along different lineages are not excessively large, however. So it is possible, in principle, to time phylogenetic events with as much accuracy as may be desired, but more genes or proteins (about two to four times as many) must be examined than would be required if the clock was stochastically constant. The average rates obtained for several proteins taken together become a fairly precise clock, particularly when many species are studied and the evolutionary events involve long time periods (on the order of 50 million years or longer).
This conclusion is illustrated in the figure, which plots the cumulative number of nucleotide changes in seven proteins against the dates of divergence of 17 species of mammals (16 pairings) as determined from the fossil record. The overall rate of nucleotide substitution is fairly uniform. Some primate species (the pairs represented by triangular points in the figure) appear to have evolved at a slower rate than the average for the rest of the species. This anomaly occurs because the more recent the divergence of any two species, the more likely it is that the changes observed will depart from the average evolutionary rate. As the length of time increases, periods of rapid and slow evolution in any lineage are likely to cancel one another out.
Evolutionists have discovered, however, that molecular time estimates tend to be systematically older than estimates based on other methods and, indeed, to be older than the actual dates. This is a consequence of the statistical properties of molecular estimates, which are asymmetrically distributed. Because of chance, the number of molecular differences between two species may be larger or smaller than expected. But overestimation errors are unbounded, whereas underestimation errors are bounded, since they cannot be smaller than zero. Consequently, a graph of a typical distribution (see normal distribution) of estimates of the age when two species diverged, gathered from a number of different genes, is skewed from the normal bell shape, with a large number of estimates of younger age clustered together at one end and a long “tail” of older-age estimates trailing away toward the other end. The average of the estimated times thus will consistently overestimate the true date. The overestimation bias becomes greater when the rate of molecular evolution is slower, the sequences used are shorter, and the time becomes increasingly remote. |
|
|
|
|
| |
The neutrality theory of molecular evolution
|
The neutrality theory of molecular evolution
The neutrality theory of molecular evolution (B)
In the late 1960s it was proposed that at the molecular level most evolutionary changes are selectively “neutral,” meaning that they are due to genetic drift rather than to natural selection. Nucleotide and amino acid substitutions appear in a population by mutation. If alternative alleles (alternative DNA sequences) have identical fitness — if they are identically able to perform their function — changes in allelic frequency from generation to generation will occur only by genetic drift. Rates of allelic substitution will be stochastically constant — that is, they will occur with a constant probability for a given gene or protein. This constant rate is the mutation rate for neutral alleles.
According to the neutrality theory, a large proportion of all possible mutants at any gene locus are harmful to their carriers. These mutants are eliminated by natural selection, just as standard evolutionary theory postulates. The neutrality theory also agrees that morphological, behavioral, and ecological traits evolve under the control of natural selection. What is distinctive in the theory is the claim that at each gene locus there are several favourable mutants, equivalent to one another with respect to adaptation, so that they are not subject to natural selection among themselves. Which of these mutants increases or decreases in frequency in one or another species is purely a matter of chance, the result of random genetic drift over time.
Neutral alleles are those that differ so little in fitness that their frequencies change by random drift rather than by natural selection. This definition is formally stated as 4Nes < 1, where Ne is the effective size of the population and s is the selective coefficient that measures the difference in fitness between the alleles.
Assume that k is the rate of substitution of neutral alleles per unit time in the course of evolution. The time units can be years or generations. In a random-mating population with N diploid individuals, k = 2Nux, where u is the neutral mutation rate per gamete per unit time (time measured in the same units as for k) and x is the probability of ultimate fixation of a neutral mutant. The derivation of this equation is straightforward: there are 2Nu mutants per time unit, each with a probability x of becoming fixed. In a population of N diploid individuals there are 2N genes at each locus, all of them, if they are neutral, with an identical probability, x = 1/(2N), of becoming fixed. If this value of x is substituted in the equation above (k = 2Nux), the result is k = u. In terms of the theory, then, the rate of substitution of neutral alleles is precisely the rate at which the neutral alleles arise by mutation, independently of the number of individuals in the population or of any other factors.
If the neutrality theory of molecular evolution is strictly correct, it will provide a theoretical foundation for the hypothesis of the molecular evolutionary clock, since the rate of neutral mutation would be expected to remain constant through evolutionary time and in different lineages. The number of amino acid or nucleotide differences between species would, therefore, simply reflect the time elapsed since they shared the last common ancestor.
Evolutionists debate whether the neutrality theory is valid. Tests of the molecular clock hypothesis indicate that the variations in the rates of molecular evolution are substantially larger than would be expected according to the neutrality theory. Other tests have revealed substantial discrepancies between the amount of genetic polymorphism found in populations of a given species and the amount predicted by the theory. But defenders of the theory argue that these discrepancies can be assimilated by modifying the theory somewhat—by assuming, for example, that alleles are not strictly neutral but their differences in selective value are quite small. Be that as it may, the neutrality theory provides a “null hypothesis,” or point of departure, for measuring molecular evolution. |
|
|
|
|
|
|
|
|
|
|
Molecular evolution
Molecular evolution (W)
|
| |
History
|
History
History (W)
The history of molecular evolution starts in the early 20th century with comparative biochemistry, and the use of "fingerprinting" methods such as immune assays, gel electrophoresis and paper chromatography in the 1950s to explore homologous proteins. The field of molecular evolution came into its own in the 1960s and 1970s, following the rise of molecular biology. The advent of protein sequencing allowed molecular biologists to create phylogenies based on sequence comparison, and to use the differences between homologous sequences as a molecular clock to estimate the time since the last universal common ancestor. In the late 1960s, the neutral theory of molecular evolution provided a theoretical basis for the molecular clock, though both the clock and the neutral theory were controversial, since most evolutionary biologists held strongly to panselectionism, with natural selection as the only important cause of evolutionary change. After the 1970s, nucleic acid sequencing allowed molecular evolution to reach beyond proteins to highly conserved ribosomal RNA sequences, the foundation of a reconceptualization of the early history of life. |
|
|
|
|
| |
Forces in molecular evolution
|
Forces in molecular evolution
Forces in molecular evolution (W)
The content and structure of a genome is the product of the molecular and population genetic forces which act upon that genome. Novel genetic variants will arise through mutation and will spread and be maintained in populations due to genetic drift or natural selection. |
|
|
|
Mutation
Mutation (W)
Mutations are permanent, transmissible changes to the genetic material (DNA or RNA) of a cell or virus. Mutations result from errors in DNA replication during cell division and by exposure to radiation, chemicals, and other environmental stressors, or viruses and transposable elements. Most mutations that occur are single nucleotide polymorphisms which modify single bases of the DNA sequence, resulting in point mutations. Other types of mutations modify larger segments of DNA and can cause duplications, insertions, deletions, inversions, and translocations.
Most organisms display a strong bias in the types of mutations that occur with strong influence in GC-content. Transitions (A ↔ G or C ↔ T) are more common than transversions (purine (adenine or guanine)) ↔ pyrimidine (cytosine or thymine, or in RNA, uracil)) and are less likely to alter amino acid sequences of proteins.
Mutations are stochastic and typically occur randomly across genes. Mutation rates for single nucleotide sites for most organisms are very low, roughly 10−9 to 10−8 per site per generation, though some viruses have higher mutation rates on the order of 10−6 per site per generation. Among these mutations, some will be neutral or beneficial and will remain in the genome unless lost via genetic drift, and others will be detrimental and will be eliminated from the genome by natural selection.
Because mutations are extremely rare, they accumulate very slowly across generations. While the number of mutations which appears in any single generation may vary, over very long time periods they will appear to accumulate at a regular pace. Using the mutation rate per generation and the number of nucleotide differences between two sequences, divergence times can be estimated effectively via the molecular clock. |
|
|
|
|
Recombination
Recombination (W)
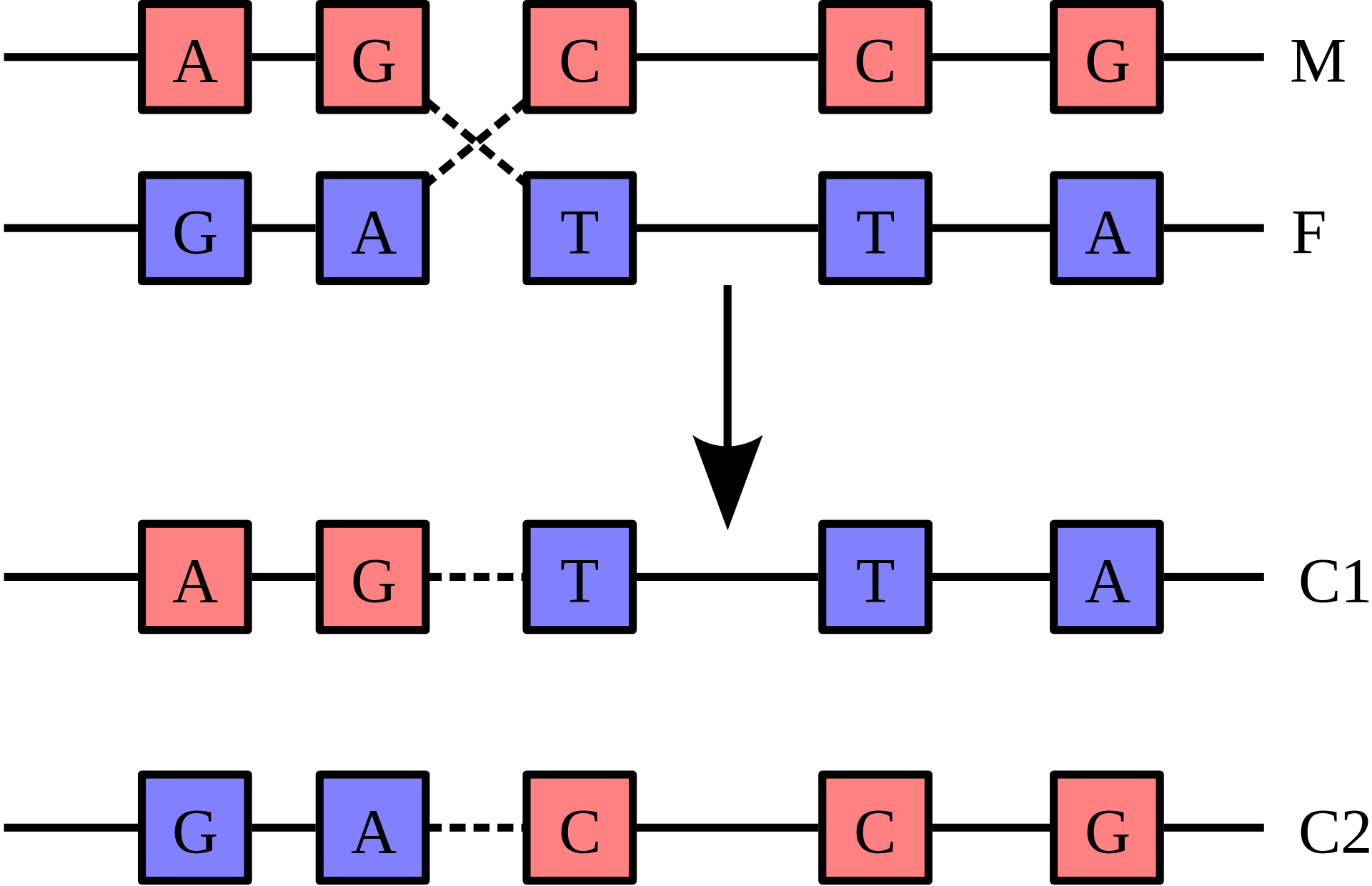
Recombination involves the breakage and rejoining of two chromosomes (M and F) to produce two re-arranged chromosomes (C1 and C2). |
|
|
| |
|
Further information: Genetic recombination
Recombination is a process that results in genetic exchange between chromosomes or chromosomal regions. Recombination counteracts physical linkage between adjacent genes, thereby reducing genetic hitchhiking. The resulting independent inheritance of genes results in more efficient selection, meaning that regions with higher recombination will harbor fewer detrimental mutations, more selectively favored variants, and fewer errors in replication and repair. Recombination can also generate particular types of mutations if chromosomes are misaligned.
|
|
|
|
Gene conversion
Gene conversion (W)
Gene conversion is a type of recombination that is the product of DNA repair where nucleotide damage is corrected using an homologous genomic region as a template. Damaged bases are first excised, the damaged strand is then aligned with an undamaged homolog, and DNA synthesis repairs the excised region using the undamaged strand as a guide. Gene conversion is often responsible for homogenizing sequences of duplicate genes over long time periods, reducing nucleotide divergence. |
|
|
|
Genetic drift
Genetic drift (W)
Genetic drift is the change of allele frequencies from one generation to the next due to stochastic effects of random sampling in finite populations. Some existing variants have no effect on fitness and may increase or decrease in frequency simply due to chance. "Nearly neutral" variants whose selection coefficient is close to a threshold value of 1 / the effective population size will also be affected by chance as well as by selection and mutation. Many genomic features have been ascribed to accumulation of nearly neutral detrimental mutations as a result of small effective population sizes. With a smaller effective population size, a larger variety of mutations will behave as if they are neutral due to inefficiency of selection. |
|
|
|
Selection
Selection (W)
Selection occurs when organisms with greater fitness, i.e. greater ability to survive or reproduce, are favored in subsequent generations, thereby increasing the instance of underlying genetic variants in a population. Selection can be the product of natural selection, artificial selection, or sexual selection. Natural selection is any selective process that occurs due to the fitness of an organism to its environment. In contrast sexual selection is a product of mate choice and can favor the spread of genetic variants which act counter to natural selection but increase desirability to the opposite sex or increase mating success. Artificial selection, also known as selective breeding, is imposed by an outside entity, typically humans, in order to increase the frequency of desired traits.
The principles of population genetics apply similarly to all types of selection, though in fact each may produce distinct effects due to clustering of genes with different functions in different parts of the genome, or due to different properties of genes in particular functional classes. For instance, sexual selection could be more likely to affect molecular evolution of the sex chromosomes due to clustering of sex specific genes on the X, Y, Z or W. |
|
|
|
|
Intragenomic conflict
Intragenomic conflict (W)
Selection can operate at the gene level at the expense of organismal fitness, resulting in intragenomic conflict. This is because there can be a selective advantage for selfish genetic elements in spite of a host cost. Examples of such selfish elements include transposable elements, meiotic drivers, killer X chromosomes, selfish mitochondria, and self-propagating introns. |
|
|
|
| |
| |
|
Genome size
Genome size (W)
Genome size is influenced by the amount of repetitive DNA as well as number of genes in an organism. The C-value paradox refers to the lack of correlation between organism 'complexity' and genome size. Explanations for the so-called paradox are two-fold. First, repetitive genetic elements can comprise large portions of the genome for many organisms, thereby inflating DNA content of the haploid genome. Secondly, the number of genes is not necessarily indicative of the number of developmental stages or tissue types in an organism. An organism with few developmental stages or tissue types may have large numbers of genes that influence non-developmental phenotypes, inflating gene content relative to developmental gene families.
Neutral explanations for genome size suggest that when population sizes are small, many mutations become nearly neutral. Hence, in small populations repetitive content and other 'junk' DNA can accumulate without placing the organism at a competitive disadvantage. There is little evidence to suggest that genome size is under strong widespread selection in multicellular eukaryotes. Genome size, independent of gene content, correlates poorly with most physiological traits and many eukaryotes, including mammals, harbor very large amounts of repetitive DNA.
However, birds likely have experienced strong selection for reduced genome size, in response to changing energetic needs for flight. Birds, unlike humans, produce nucleated red blood cells, and larger nuclei lead to lower levels of oxygen transport. Bird metabolism is far higher than that of mammals, due largely to flight, and oxygen needs are high. Hence, most birds have small, compact genomes with few repetitive elements. Indirect evidence suggests that non-avian theropod dinosaur ancestors of modern birds also had reduced genome sizes, consistent with endothermy and high energetic needs for running speed. Many bacteria have also experienced selection for small genome size, as time of replication and energy consumption are so tightly correlated with fitness. |
|
|
|
|
Repetitive elements
Repetitive elements (W)
Transposable elements are self-replicating, selfish genetic elements which are capable of proliferating within host genomes. Many transposable elements are related to viruses, and share several proteins in common. |
|
|
|
Chromosome number and organization
Chromosome number and organization (W)
The number of chromosomes in an organism's genome also does not necessarily correlate with the amount of DNA in its genome. The ant Myrmecia pilosula has only a single pair of chromosomes whereas the Adders-tongue fern Ophioglossum reticulatum has up to 1260 chromosomes. Cilliate genomes house each gene in individual chromosomes, resulting in a genome which is not physically linked. Reduced linkage through creation of additional chromosomes should effectively increase the efficiency of selection.
Changes in chromosome number can play a key role in speciation, as differing chromosome numbers can serve as a barrier to reproduction in hybrids. Human chromosome 2 was created from a fusion of two chimpanzee chromosomes and still contains central telomeres as well as a vestigial second centromere. Polyploidy, especially allopolyploidy, which occurs often in plants, can also result in reproductive incompatibilities with parental species. Agrodiatus blue butterflies have diverse chromosome numbers ranging from n=10 to n=134 and additionally have one of the highest rates of speciation identified to date. |
|
|
|
|
Gene content and distribution
Gene content and distribution (W)
Different organisms house different numbers of genes within their genomes as well as different patterns in the distribution of genes throughout the genome. Some organisms, such as most bacteria, Drosophila, and Arabidopsis have particularly compact genomes with little repetitive content or non-coding DNA. Other organisms, like mammals or maize, have large amounts of repetitive DNA, long introns, and substantial spacing between different genes. The content and distribution of genes within the genome can influence the rate at which certain types of mutations occur and can influence the subsequent evolution of different species. Genes with longer introns are more likely to recombine due to increased physical distance over the coding sequence. As such, long introns may facilitate ectopic recombination, and result in higher rates of new gene formation. |
|
|
|
Organelles
Organelles (W)
In addition to the nuclear genome, endosymbiont organelles contain their own genetic material typically as circular plasmids. Mitochondrial and chloroplast DNA varies across taxa, but membrane-bound proteins, especially electron transport chain constituents are most often encoded in the organelle. Chloroplasts and mitochondria are maternally inherited in most species, as the organelles must pass through the egg. In a rare departure, some species of mussels are known to inherit mitochondria from father to son. |
|
|
|
| |
Origins of new genes
|
Origins of new genes
Origins of new genes (W)
New genes arise from several different genetic mechanisms including gene duplication, de novo origination, retrotransposition, chimeric gene formation, recruitment of non-coding sequence, and gene truncation.
Gene duplication initially leads to redundancy. However, duplicated gene sequences can mutate to develop new functions or specialize so that the new gene performs a subset of the original ancestral functions. In addition to duplicating whole genes, sometimes only a domain or part of a protein is duplicated so that the resulting gene is an elongated version of the parental gene.
Retrotransposition creates new genes by copying mRNA to DNA and inserting it into the genome. Retrogenes often insert into new genomic locations, and often develop new expression patterns and functions.
Chimeric genes form when duplication, deletion, or incomplete retrotransposition combine portions of two different coding sequences to produce a novel gene sequence. Chimeras often cause regulatory changes and can shuffle protein domains to produce novel adaptive functions.
De novo gene birth can also give rise to new genes from previously non-coding DNA. For instance, Levine and colleagues reported the origin of five new genes in the D. melanogaster genome from noncoding DNA. Similar de novo origin of genes has been also shown in other organisms such as yeast, rice and humans. De novo genes may evolve from transcripts that are already expressed at low levels. Mutation of a stop codon to a regular codon or a frameshift may cause an extended protein that includes a previously non-coding sequence. The formation of novel genes from scratch typically can not occur within genomic regions of high gene density. The essential events for de novo formation of genes is recombination/mutation which includes insertions, deletions, and inversions. These events are tolerated if the consequence of these genetic events does not interfere in cellular activities. Most genomes comprise prophages wherein genetic modifications do not, in general, affect the host genome propagation. Hence, there is higher probability of genetic modifications, in regions such as prophages, which is proportional to the probability of de novo formation of genes.
De novo evolution of genes can also be simulated in the laboratory. For example, semi-random gene sequences can be selected for specific functions. More specifically, they selected sequences from a library that could complement a gene deletion in E. coli. The deleted gene encodes ferric enterobactin esterase (Fes), which releases iron from an iron chelator, enterobactin. While Fes is a 400 amino acid protein, the newly selected gene was only 100 amino acids in length and unrelated in sequence to Fes. |
|
|
|
|
| |
In vitro molecular evolution experiments
|
In vitro molecular evolution experiments
In vitro molecular evolution experiments (W)
Principles of molecular evolution have also been discovered, and others elucidated and tested using experimentation involving amplification, variation and selection of rapidly proliferating and genetically varying molecular species outside cells. Since the pioneering work of Sol Spiegelmann in 1967 [ref], involving RNA that replicates itself with the aid of an enzyme extracted from the Qß virus [ref], several groups (such as Kramers [ref] and Biebricher/Luce/Eigen [ref]) studied mini and micro variants of this RNA in the 1970s and 1980s that replicate on the timescale of seconds to a minute, allowing hundreds of generations with large population sizes (e.g. 10^14 sequences) to be followed in a single day of experimentation. The chemical kinetic elucidation of the detailed mechanism of replication [ref, ref] meant that this type of system was the first molecular evolution system that could be fully characterised on the basis of physical chemical kinetics, later allowing the first models of the genotype to phenotype map based on sequence dependent RNA folding and refolding to be produced [ref, ref]. Subject to maintaining the function of the multicomponent Qß enzyme, chemical conditions could be varied significantly, in order to study the influence of changing environments and selection pressures [ref]. Experiments with in vitro RNA quasi species included the characterisation of the error threshold for information in molecular evolution [ref], the discovery of de novo evolution [ref] leading to diverse replicating RNA species and the discovery of spatial travelling waves as ideal molecular evolution reactors [ref, ref]. Later experiments employed novel combinations of enzymes to elucidate novel aspects of interacting molecular evolution involving population dependent fitness, including work with artificially designed molecular predator prey and cooperative systems of multiple RNA and DNA [ref, ref]. Special evolution reactors were designed for these studies, starting with serial transfer machines, flow reactors such as cell-stat machines, capillary reactors, and microreactors including line flow reactors and gel slice reactors. These studies were accompanied by theoretical developments and simulations involving RNA folding and replication kinetics that elucidated the importance of the correlation structure between distance in sequence space and fitness changes [ref], including the role of neutral networks and structural ensembles in evolutionary optimisation. |
|
|
|
|
| |
Molecular phylogenetics
|
Molecular phylogenetics
Molecular phylogenetics (W)
Molecular systematics is the product of the traditional fields of systematics and molecular genetics. It uses DNA, RNA, or protein sequences to resolve questions in systematics, i.e. about their correct scientific classification or taxonomy from the point of view of evolutionary biology.
Molecular systematics has been made possible by the availability of techniques for DNA sequencing, which allow the determination of the exact sequence of nucleotides or bases in either DNA or RNA. At present it is still a long and expensive process to sequence the entire genome of an organism, and this has been done for only a few species. However, it is quite feasible to determine the sequence of a defined area of a particular chromosome. Typical molecular systematic analyses require the sequencing of around 1000 base pairs. |
|
|
|
The driving forces of evolution
The driving forces of evolution (W)
Depending on the relative importance assigned to the various forces of evolution, three perspectives provide evolutionary explanations for molecular evolution.
Selectionist hypotheses argue that selection is the driving force of molecular evolution. While acknowledging that many mutations are neutral, selectionists attribute changes in the frequencies of neutral alleles to linkage disequilibrium with other loci that are under selection, rather than to random genetic drift. Biases in codon usage are usually explained with reference to the ability of even weak selection to shape molecular evolution.
Neutralist hypotheses emphasize the importance of mutation, purifying selection, and random genetic drift. The introduction of the neutral theory by Kimura, quickly followed by King and Jukes' own findings, led to a fierce debate about the relevance of neodarwinism at the molecular level. The Neutral theory of molecular evolution proposes that most mutations in DNA are at locations not important to function or fitness. These neutral changes drift towards fixation within a population. Positive changes will be very rare, and so will not greatly contribute to DNA polymorphisms. Deleterious mutations do not contribute much to DNA diversity because they negatively affect fitness and so are removed from the gene pool before long. This theory provides a framework for the molecular clock. The fate of neutral mutations are governed by genetic drift, and contribute to both nucleotide polymorphism and fixed differences between species.
In the strictest sense, the neutral theory is not accurate. Subtle changes in DNA very often have effects, but sometimes these effects are too small for natural selection to act on. Even synonymous mutations are not necessarily neutral because there is not a uniform amount of each codon. The nearly neutral theory expanded the neutralist perspective, suggesting that several mutations are nearly neutral, which means both random drift and natural selection is relevant to their dynamics. The main difference between the neutral theory and nearly neutral theory is that the latter focuses on weak selection, not strictly neutral.
Mutationists hypotheses emphasize random drift and biases in mutation patterns. Sueoka was the first to propose a modern mutationist view. He proposed that the variation in GC content was not the result of positive selection, but a consequence of the GC mutational pressure. |
|
|
|
|
| |
Protein evolution
|
Protein evolution
Protein evolution (W)
Evolution of proteins is studied by comparing the sequences and structures of proteins from many organisms representing distinct evolutionary clades. If the sequences/structures of two proteins are similar indicating that the proteins diverged from a common origin, these proteins are called as homologous proteins. More specifically, homologous proteins that exist in two distinct species are called orthologs. Whereas, homologous proteins encoded by the genome of a single species are called paralogs.
The phylogenetic relationships of proteins are examined by multiple sequence comparisons. Phylogenetic trees of proteins can be established by the comparison of sequence identities among proteins. Such phylogenetic trees have established that the sequence similarities among proteins reflect closely the evolutionary relationships among organisms.
Protein evolution describes the changes over time in protein shape, function, and composition. Through quantitative analysis and experimentation, scientists have strived to understand the rate and causes of protein evolution. Using the amino acid sequences of hemoglobin and cytochrome c from multiple species, scientists were able to derive estimations of protein evolution rates. What they found was that the rates were not the same among proteins. Each protein has its own rate, and that rate is constant across phylogenies (i.e., hemoglobin does not evolve at the same rate as cytochrome c, but hemoglobins from humans, mice, etc. do have comparable rates of evolution.). Not all regions within a protein mutate at the same rate; functionally important areas mutate more slowly and amino acid substitutions involving similar amino acids occurs more often than dissimilar substitutions. Overall, the level of polymorphisms in proteins seems to be fairly constant. Several species (including humans, fruit flies, and mice) have similar levels of protein polymorphism.
In his Dublin 1943 lectures, “What Is Life?”, Erwin Schrodinger proposed that we could progress in answering this question by using statistical mechanics and partition functions, but not quantum mechanics and his wave equation. He described an “aperiodic crystal” which could carry genetic information, a description credited by Francis Crick and James D. Watson with having inspired their discovery of the double helical structure of DNA </ref>{{cite journal|last= Holliday|first=Robin|title = Physics and the origins of molecular biology|journal = Journal of Genetics|volume= 85|pages=93-97|year=(2006) Moret, Marcelo; Zebende, Gilney (January 2007). "Amino acid hydrophobicity and accessible surface area". Physical Review E. 75 (1): 011920. </ref>. The existence of these fractals proves that proteins function near critical points of second-order phase transitions, realizing Schrodinger's conjecture. It opens a new biophysics field of accurate thermodynamic analysis of protein evolution based primarily on amino acid sequences </ref>{{cite journal|last =Phillips|first=James|title = Fractals and self-organized criticality in proteins|journal = Physica A|volume= 415 |pages = 440-448 |year=(2014)</ref> |
| |
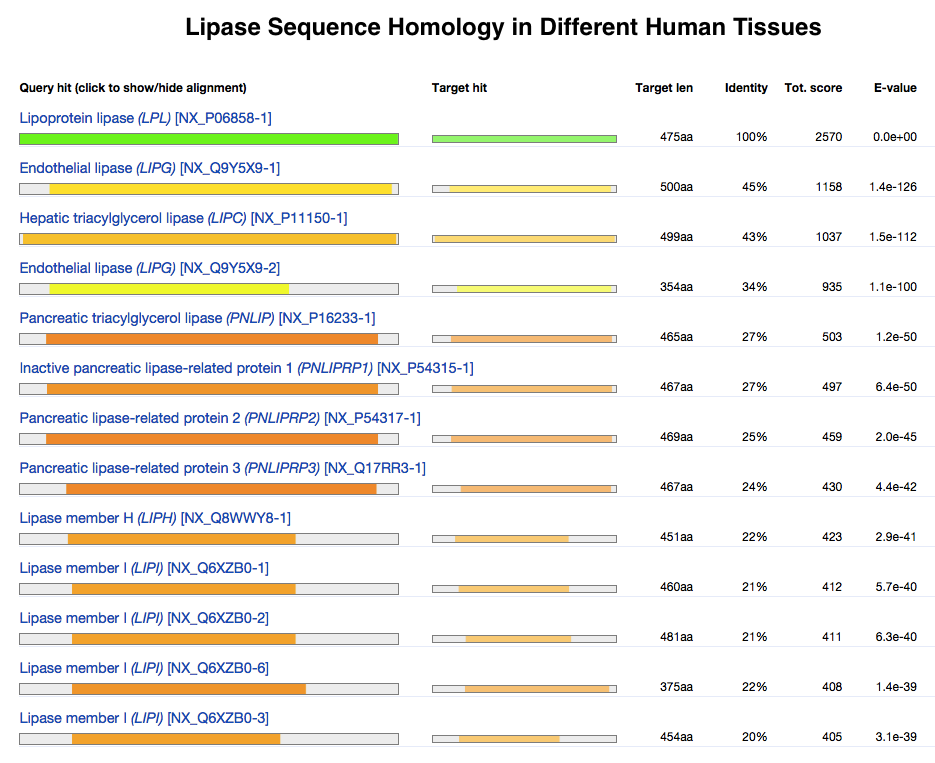
This chart compares the sequence identity of different lipase proteins throughout the human body. It demonstrates how proteins evolve, keeping some regions conserved while others change dramatically. |
|
|
|
|
|
| |
Relation to nucleic acid evolution
|
Relation to nucleic acid evolution
Relation to nucleic acid evolution (W)
Protein evolution is inescapably tied to changes and selection of DNA polymorphisms and mutations because protein sequences change in response to alterations in the DNA sequence. Amino acid sequences and nucleic acid sequences do not mutate at the same rate. Due to the degenerate nature of DNA, bases can change without affecting the amino acid sequence. For example, there are six codons that code for leucine. Thus, despite the difference in mutation rates, it is essential to incorporate nucleic acid evolution into the discussion of protein evolution. At the end of the 1960s, two groups of scientists—Kimura (1968) and King and Jukes (1969)—independently proposed that a majority of the evolutionary changes observed in proteins were neutral. Since then, the neutral theory has been expanded upon and debated. |
|
|
|
Discordance with morphological evolution
|
|
|
|
|
|
|
|
|
| |
Neutral theory of molecular evolution (W) |
Neutral theory of molecular evolution
Neutral theory of molecular evolution (W)
The neutral theory of molecular evolution holds that most evolutionary changes at the molecular level, and most of the variation within and between species, are due to random genetic drift of mutant alleles that are selectively neutral. The theory applies only for evolution at the molecular level, and is compatible with phenotypic evolution being shaped by natural selection as postulated by Charles Darwin. The neutral theory allows for the possibility that most mutations are deleterious, but holds that because these are rapidly removed by natural selection, they do not make significant contributions to variation within and between species at the molecular level. A neutral mutation is one that does not affect an organism's ability to survive and reproduce. The neutral theory assumes that most mutations that are not deleterious are neutral rather than beneficial. Because only a fraction of gametes are sampled in each generation of a species, the neutral theory suggests that a mutant allele can arise within a population and reach fixation by chance, rather than by selective advantage.
The theory was introduced by the Japanese biologist Motoo Kimura in 1968, and independently by two American biologists Jack Lester King and Thomas Hughes Jukes in 1969, and described in detail by Kimura in his 1983 monograph The Neutral Theory of Molecular Evolution. The proposal of the neutral theory was followed by an extensive "neutralist-selectionist" controversy over the interpretation of patterns of molecular divergence and gene polymorphism, peaking in the 1970s and 1980s. |
|
| |
| |
Origins
|
Origins
Origins (W)
While some scientists, such as Freese (1962) and Freese and Yoshida (1965), had suggested that neutral mutations were probably widespread, a coherent theory of neutral evolution was proposed by Motoo Kimura in 1968,[4] and by King and Jukes independently in 1969. Kimura initially focused on differences among species, King and Jukes on differences within species.
Many molecular biologists and population geneticists also contributed to the development of the neutral theory. Principles of population genetics, established by J.B.S. Haldane, R.A. Fisher and Sewall Wright, created a mathematical approach to analyzing gene frequencies that contributed to the development of Kimura's theory.
Haldane's dilemma regarding the cost of selection was used as motivation by Kimura. Haldane estimated that it takes about 300 generations for a beneficial mutation to become fixed in a mammalian lineage, meaning that the number of substitutions (1.5 per year) in the evolution between humans and chimpanzees was too high to be explained by beneficial mutations. |
|
|
|
|
| |
Functional constraint
|
Functional constraint
Functional constraint (W)
The neutral theory holds that as functional constraint diminishes, the probability that a mutation is neutral rises, and so should the rate of sequence divergence.
When comparing various proteins, extremely high evolutionary rates were observed in proteins such as fibrinopeptides and the C chain of the proinsulin molecule, which both have little to no functionality compared to their active molecules. Kimura and Ohta also estimated that the alpha and beta chains on the surface of a hemoglobin protein evolve at a rate almost ten times faster than the inside pockets, which would imply that the overall molecular structure of hemoglobin is less significant than the inside where the iron-containing heme groups reside.
There is evidence that rates of nucleotide substitution are particularly high in the third position of a codon, where there is little functional constraint. This view is based in part on the degenerate genetic code, in which sequences of three nucleotides (codons) may differ and yet encode the same amino acid (GCC and GCA both encode alanine, for example). Consequently, many potential single-nucleotide changes are in effect "silent" or "unexpressed" (see synonymous or silent substitution). Such changes are presumed to have little or no biological effect. |
|
|
|
|
| |
Quantitative theory
|
Quantitative theory
Quantitative theory (W)
Kimura also developed the infinite sites model (ISM) to provide insight into evolutionary rates of mutant alleles. If v were to represent the rate of mutation of gametes per generation of N individuals, each with two sets of chromosomes, the total number of new mutants in each generation is 2Nv. Now let k represent the evolution rate in terms of a mutant allele m becoming fixed in a population.
k= 2Nvm
According to ISM, selectively neutral mutations appear at rate m in each of the 2N copies of a gene, and fix with probability 1/(2N). Because any of the 2N genes have the ability to become fixed in a population, 1/2N is equal to m, resulting in the rate of evolutionary rate equation:
k=v.
This means that if all mutations were neutral, the rate at which fixed differences accumulate between divergent populations is predicted to be equal to the per-individual mutation rate, independent of population size. When the proportion of mutations that are neutral is constant, so is the divergence rate between populations. This provides a rationale for the molecular clock - which predated neutral theory. The ISM also demonstrates a constancy that is observed in molecular lineages.
This stochastic process is assumed to obey equations describing random genetic drift by means of accidents of sampling, rather than for example genetic hitchhiking of a neutral allele due to genetic linkage with non-neutral alleles. After appearing by mutation, a neutral allele may become more common within the population via genetic drift. Usually, it will be lost, or in rare cases it may become fixed, meaning that the new allele becomes standard in the population.
According to the neutral theory of molecular evolution, the amount of genetic variation within a species should be proportional to the effective population size. |
|
|
|
|
The "neutralist–selectionist" debate
The “neutralist–selectionist” debate (W)
A heated debate arose when Kimura's theory was published, largely revolving around the relative percentages of polymorphic and fixed alleles that are "neutral" versus "non-neutral".
A genetic polymorphism means that different forms of particular genes, and hence of the proteins that they produce, are co-existing within a species. Selectionists claimed that such polymorphisms are maintained by balancing selection, while neutralists view the variation of a protein as a transient phase of molecular evolution. Studies by Richard K. Koehn and W. F. Eanes demonstrated a correlation between polymorphism and molecular weight of their molecular subunits. This is consistent with the neutral theory assumption that larger subunits should have higher rates of neutral mutation. Selectionists, on the other hand, contribute environmental conditions to be the major determinants of polymorphisms rather than structural and functional factors.
According to the neutral theory of molecular evolution, the amount of genetic variation within a species should be proportional to the effective population size. Levels of genetic diversity vary much less than census population sizes, giving rise to the "paradox of variation" . While high levels of genetic diversity were one of the original arguments in favor of neutral theory, the paradox of variation has been one of the strongest arguments against neutral theory.
There are a large number of statistical methods for testing whether neutral theory is a good description of evolution (e.g., McDonald-Kreitman test), and many authors claimed detection of selection (Fay et al. 2002, Begun et al. 2007, Shapiro et al. 2007, Hahn 2008, Akey 2009, Kern 2018). Some researchers have nevertheless argued that the neutral theory still stands, while expanding the definition of neutral theory to include background selection at linked sites. |
|
|
|
|
|
|
|
|
|
|